日志满了
收到告警 clickhouse-zookeeper 的告警

zookeeper 其实是有参数可以实现自动清理以前的数据
1 | # 间隔多久进行一次清理 |
zookeeper 上如果没有设置autopurge.purgeInterval参数, 默认是 0, 表示关闭自动清理
导致数据一直保留着, 把磁盘写满了(其实也就 10G, 小规模的集群)
因为使用 helm 部署的 zookeeper, 参数都是通过环境变量控制的
所以需要通过 stateful 的配置来修改这个ZOO_AUTOPURGE_INTERVAL参数
无法启动 pod
通过 qcloud k8s 的界面修改完了后, 发现 pod 无法启动
一直在报这个错误Back-off restarting failed container
根据之前的经验, 都是因为 pod 里面的进程执行错误导致的
一般都能在日志里面找到相关的错误信息, 但是这次什么都没有.
而且因为 pod 一直在重启, 也无法登录进 container 里面
尝试还原修改, 问题依然存在.
既然如此, 那就修改 pod 的command, 通过tail -f /dev/null让 pod 保持住
然而当我打开编辑界面时发现不对劲啊, 命令和参数全乱套了.

我做了啥, 只不过修改了一个环境变量而已
看来编辑器不可靠, 直接打开了 stateful 的 yaml 文件, 并且找到另一个 zookeeper 的 yaml 文件进行对比
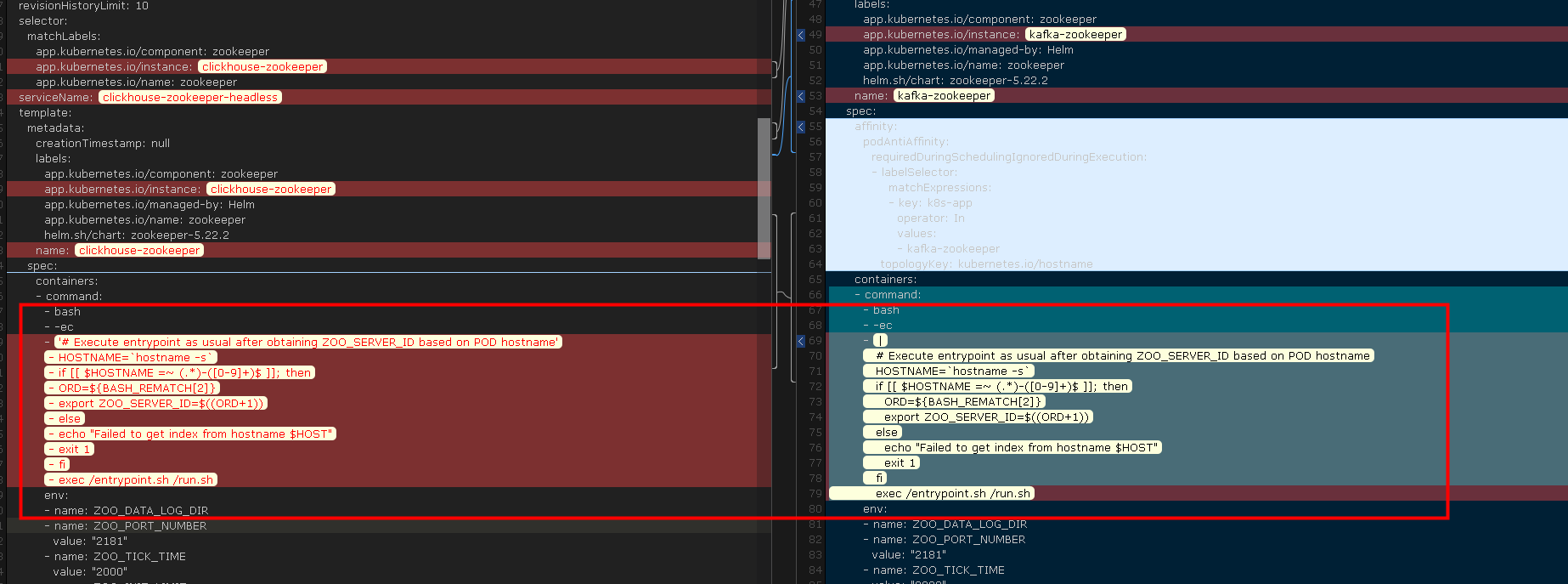
左边是有问题的, 右边是正常的.
很明显, 在使用 qcloud k8s 编辑器的时候, 将换行都转成了参数.
导致 pod 运行不起来.
总结
- 以为是小问题, 修改不会有影响, 结果还是坑了自己
- 云厂商的也不太可靠啊, 能写 yaml 还是写 yaml 吧
- 因为是用来测试的, 所以部署时也没有考虑清理数据的问题