背景
游戏行业的滚服需求, 服务之间相互独立
每天有大量的服务部署需求
并且在保证稳定的前提下尽可能的提高资源利用率
而且还有个问题, 我们没有购买主机的权限
需要先由我们下订单, 然后通过邮件通知合作方完成订单的支付
这就导致需要预留一定数量的主机, 避免支付响应不及时引发的运营事故
问题
我们这里解决问题的是如何实现自动部署
可能一些老司机说, 自动部署嘛, 这还不简单
写个页面, 然后调用 Ansible 一下子就完成了.
但是我们想要做的是完全自动化
整个流程无人介入(不出问题的情况下)
PS: 只是部署, 不负责发布上线
方案
有图有状况…
功能图
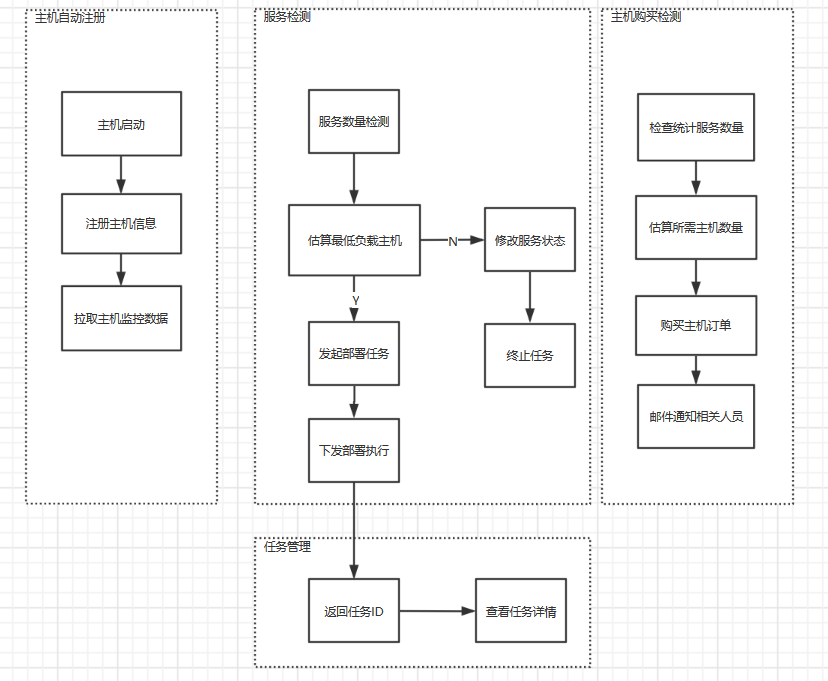
新主机自动注册
使用 SaltStack 实现主机的注册
当新云主机启动时会自动连上 Salt-Master
进行初始化以及将云主机信息注册到 CMDB
部署检测和调度
使用 Crontab 每 10 分钟检测一次(确实 Low, 但是香)
如果未使用服务数量不足
则根据资源历史使用情况进行筛选部署的主机
任务执行和查看
确定了部署的主机后, 通过 HTTP 请求新建一个部署任务
任务系统负责将需要执行的任务转化为 SaltStack 的 State
SaltStack 将执行完成后的结果保存进 Mongodb 以便查看
新主机购买通知
又是 Crontab, 我们基本上一天购买一批主机
在固定的时间点, 检测服务部署的失败次数(没有低负载的机器)
然后根据失败的服务数量大致的判断需要购买多少主机
最后通过 API 接口下订单, 发邮件通知合作方
架构图
因为我们整体的规模不是很大
所有架构方面做的很简单(维护成本低)
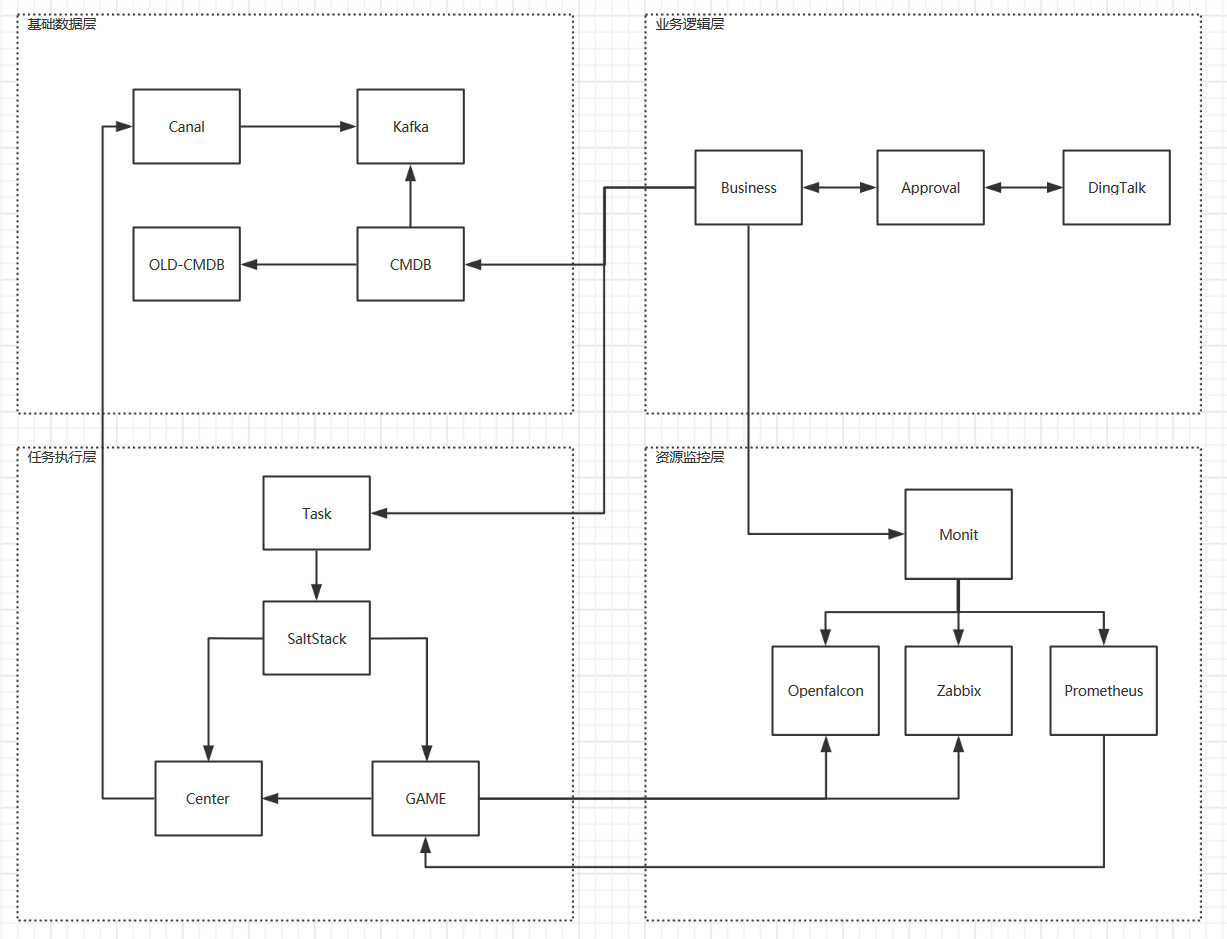
基础数据层
所有的资源和服务的状态
OLD-CMDB 是历史包袱, 研发用于更新和维护的数据
Canal, Kafka 是用于实时同步服务的状态(是否上线)
CMDB 基于 HTTP 接口为其他系统提供数据支持
CMDB 就应该是干干净净的配置管理数据库
其他业务逻辑应该在上层封装避免数据和逻辑的耦合
业务逻辑层
封装所有的业务逻辑和任务执行所需要的数据, 所有的业务逻辑都在这层体现
Approval 是为了与办公通信软件进行交互的, 我们这里使用 DingTalk 来走流程.
(走流程的目的是同步信息避免干完事后发现关键人员毫不知情)
任务执行层
在 SaltStack 上封装一层任务系统
用来解耦任务状态以及记录任务的执行的数据
这里的 SaltStack 也可以替换成 Ansible, Puppet
任务执行过程中如果进行干预还没有一个较好的方案
一个思路是通过 SaltStack 的 Event 来实现(耦合了)
资源监控层
监控主机和服务的资源使用情况
同样提供统一的接口给外部使用
这里为什么使用了三个不同的监控系统
Zabbix 之前的监控, 所以不想改动, 但是性能已经不能满足需求了
OpenFalcon 是专为自动化而搭建的监控系统, 设计的 JSON 格式非常灵活, 但存储和接口不太好用
Prometheus 只是进行尝试, PromSql 很灵活, 性能优秀, 但可扩展性比较复杂, 更像是一个组件
实施
部署检测和调度
检测
上面也提到了, 我们使用 Crontab 定时检测部署的服务是否够用
这里有个问题需要解决, 到底预留多少个空闲的服务呢?
有些平台开服很快, 一天 10 个服还不够.
有些平台开服龟速, 一星期开不到 1 个服.
写个常量肯定是不行的, 自己骗自己.
要不通过配置的方式人工的去调整…
一开始确实是这么想的, 先搞起来后面在优化.
但有同事表示完全没有人会去主动的做调整.
最后我们决定通过每个平台的最近开服数来动态判断.
这个方案可以是可以, 缺点就是自动部署就依赖了外部的系统.
导致扩展性和兼容性很差, 尤其是跨部门的情况下.
容易出现对方要改, 我们崩溃, 我们要改, 对方不理.
也没更好的办法了, 先这么搞吧…
调度
这块是个重点, 详细说起来有点像王大妈的裹脚布
简单概括一下, 是这么个思路
1 | 占用资源最大的服务 = 获取最近上线占用资源最大的服务() |
然后就能找到了最低负载的机器
如果没有的话, 就终止任务, 等待下个检测周期
牛奶和机器总会有的…
任务执行和查看
在任务系统将任务的信息转化为 SaltStack 的 State
然后通过 SaltStack 的 API 去执行
最后将执行的结果保存在 Mongodb 中.
同时用 Crontab 每分钟跑一个定时脚本
找到执行超时的和执行失败的任务并发送报警通知
收到报警时, 我们可以查看任务执行时的详细情况来解决隐患
新主机购买通知
先来想想, 什么时候需要购买新的主机.
在当部署服务时找不低负载主机, 肯定不能触发购买行为
因为, 每次找不到低负载主机就触发, 结果就是一天购买十几次的主机
(我们没权限直接购买支付, 只能下单, 由合作方支付, 非常高的协作成本和时间成本)
这时候就要将服务状态修改成等待资源状态.
这个状态是为了让购买主机的程序知道, 到底需要购买多少个主机
等待购买主机的任务检测时进行下单并且通知合作方
即使是服务状态已经是等待资源了, 在部署的流程里依然需要进行尝试部署
因为不能说上一次没有部署成功, 这一次就不能部署成功
资源的使用情况是会随时改变的.
新主机自动注册
我们在购买云主机的时候, 会使用事先制作好的镜像.
将 Salt-Minion 装在镜像里, 启动时会自动的连上 Salt-Master
进行初始化以及注册到 CMDB 上
这里有个问题是用什么来作为主机的唯一标识.
实例 ID? 主机名? 内网 IP? 公网 IP? 还是自定义?
实例 ID 或许是个好主意, 但是有些奇奇怪怪的问题.
比如不同公有云的实例 ID 是否会冲突
又比如如果我们使用私有云或者没有实例 ID 的公有云怎么办.
主机名也有些同样的问题, 主机名是否会冲突
如果修改了主机名这个主机还是这个主机吗?
内网 IP, 这个不用想肯定会冲突.
公网 IP 又会有没有公网 IP 的主机情况或者是 NAT 模式的情况.
云厂商+区域+实例 ID 是一个比较好的方案.
但是我们用的是 云厂商配置名(云厂商+区域)+内网 IP
这种方式, 主要是因为, 当时我们没有找到在主机内获取主机实例 ID 的方式
其次云厂商配置名+内网 IP 的方案会更加的通用.
效果
全都自动了, 能有啥好看的…
总结
总的来说效率不错.
解放了人力, 并且保证了质量和效率.
期间也修修补补了很多次(调参)
在兼容性和扩展性的还不是很满意
这个涉及到运维基础的标准和项目的不同需求.
很难做到一套通用, 只能将通用的部署抽出来.
不同的细节通过脚本来定制化.