背景
我们是一家 H5 的游戏公司
多数项目的服务端使用 SKYNET+LUA 的形式开发
协议层走的的 websocket
问题
1 | 一般情况下我们都是走这样的流程 |
方案
我们采用目前主流的 ELK 方案来解决这个问题
使用 elasticsearch 在日志存储
使用 logstash 做日志标准化
使用 kibana 做统计展示
另外
使用 filebeat 来做日志收集
使用使用 Crontab, Python 在实现日志监控
使用 DingTalk 接受告警信息
使用 ELK 是因为主流, 坑少, 资料多(不喜欢 java, 太笨重)
使用 filebeat 是因为原配, 小三的不要(漂亮的还是可以考虑的)
使用 Crontab, Python 是因为 es 的 watch 不能满足我们(需求第一)
使用 DingTalk 就要问老板了(老板第一)
没有使用 Kafka 是因为没有数据级和可靠性的需求
即使后面有了需求, 加入 Kafka 也不是多大的事
看图…
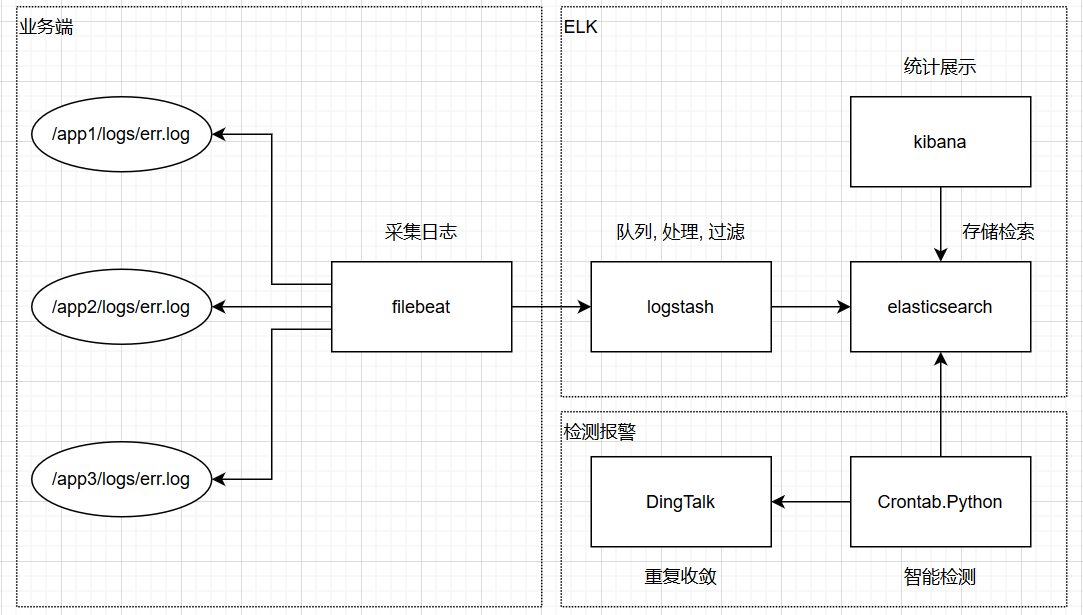
实施
filebeat
1 | 1. 使用Saltstack部署filebeat并且以后主机上线后会自动部署 |
logstash
先来看看配置文件
1 | # 多少个干活的 |
然后是 logstash 的 pipeline
这里举一小段例子
1 | # 匹配服务端超时的日志 |
因为我们的日志格式都是非标准的, 日志等级也是很随便的
这就需要我们针对每个项目的格式进行转换和处理
以保证最终的格式都是一致的(制定了标准也很难推进)
elasticsearch
配置就不说了, 都是标配
主要注意的是分片和 index 名字的管理
主分片为节点数(最高写入)
副本数为 1(数据不丢)
同一个主分片和副本不能在一台机器上, 不然机器挂了就完了
单个分片的大小在内存大小左右就行了, 毕竟是要把数据装入内存
index 的名字要么使用日期的形式命名要么使用 ilm 来自动管理
使用日期可以灵活的对某一个日期的 index 做处理
但是需要手动删除过期的数据使用 ilm 管理就只能通过 RESTAPI 来进行数据处理
好处是不用自己删除过期数据
kibana
主要使用的是 TSVB 组件和 TABLE 组件
这个 TSVB 组件还不错, 就是有些需求实现不了
可能是我学艺不精, 毕竟才用了一个月
table 组件也是奇葩的很, 创建的时候就指定了 index name.
每次都只能修改 kibana 的 obejct 也是心累啊
监控检测
前面也提到为什么我们没有使用 es 的 watch 功能
主要是希望能提高告警的准确性反应出问题
我们策略是这样的, 取一小时内的数据
1 | 当前异常比 = 当前异常数 / 当前用户数 |
这里还可以优化一下
即使当前的相差比昨天的大, 也不能隔一小时报警一次.
违背了我们的初心, 所以升级一下策略
1 | 昨日相差异常比 = 当前异常比 / 昨日异常比 |
为什么是 > 2, 这个也是拍脑袋想的
目前暂时没有想到更好的方法来动态调整.
有一个思路是根据异常数的差算出临界值, 只是一种思路.
报警通知
我们在 DingTalk 上封装了一层接口
- 集成各种报警第三方接口
- 实现告警的重复收敛
目前我们 Crontab 的时间间隔是一小时.
这个时间间隔目前来看可能没有太大的问题.
随着项目的发展, 可能会出现报警不及时的问题.
所以需要配合重复收敛功能来实现及时告警, 同时又不会重复的告警
完美…
效果
先看效果, 再谈疗程(屏蔽业务数据)
统计效果
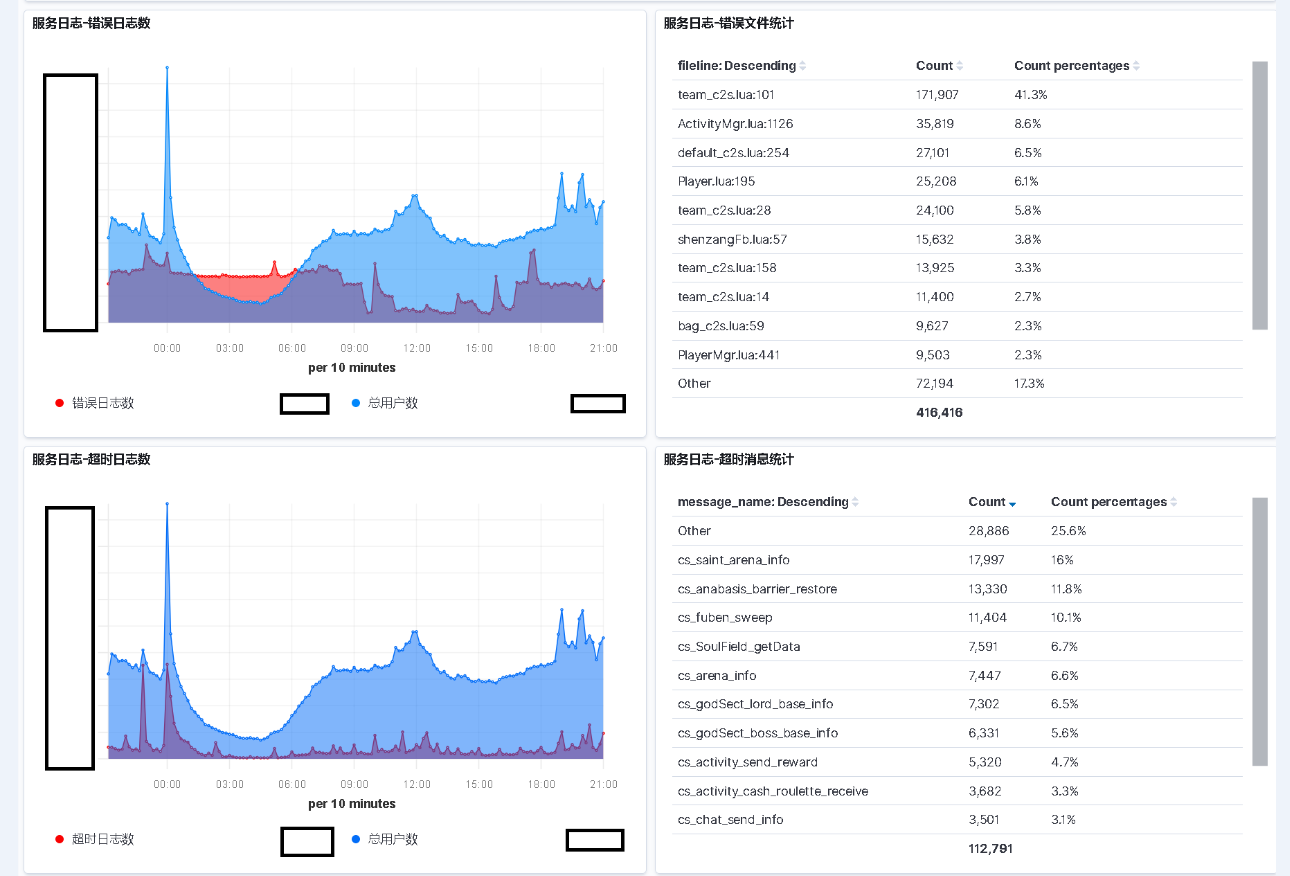
监控效果

这里说说为啥会有个用户数的指标.
我们是这么考虑的
单纯的看日志的异常数是不准确的.
因为日志的异常数是随着玩家的增加而增加的.
很容易出现, 同样一个问题, 因为玩家增加而多次报警.
形成”狼来了”的感觉
所以这里使用用户数来做参考.
这里的用户数是登录数.
其实使用在线用户数效果会更好.
只是实现的成本较高, 以后再进行迭代.
总结
首先这个系统做下来来, 用过的研发都说好.
毕竟研发也没有时间天天去看日志.
每次等用户发现 BUG 反馈过来, 太过于被动了.
其次, 通过聚合统计能够发现影响重大的在哪, 集中发力
当然也有一些问题存在
目前无法快速的接入项目
运维标准化和日志标准化的问题
每个项目可能会有不同的监控需求只监控了错误日志, 用户请求的超时并没有监控.
研发已经没有精力做体验上的优化了, 卡个几秒大家觉得可以接受了.异常信息挖掘
集合其他主机监控, 服务指标, 业务指标来从多维度来快速定位问题.只能发现问题, 没法解决问题
如果产品初期管理不善, 那积累起来的历史问题会完全无从下手
以上