背景问题
公司需要对用户的行为做分析
所以在服务端上通过 HTTP 的方式上报数据
想要将上报数据的网关容器化了
方面以后的维护和管理
因为节点少, 相对于 K8S 来说太重了.
所以准备尝试一下 Docker Swarm
没想到在测试环境没问题, 一上生产.
结果立马出现了一大堆上报失败的错误
吓的我立马回滚了操作, 再慢慢来排查.
排查思路
先看看架构图
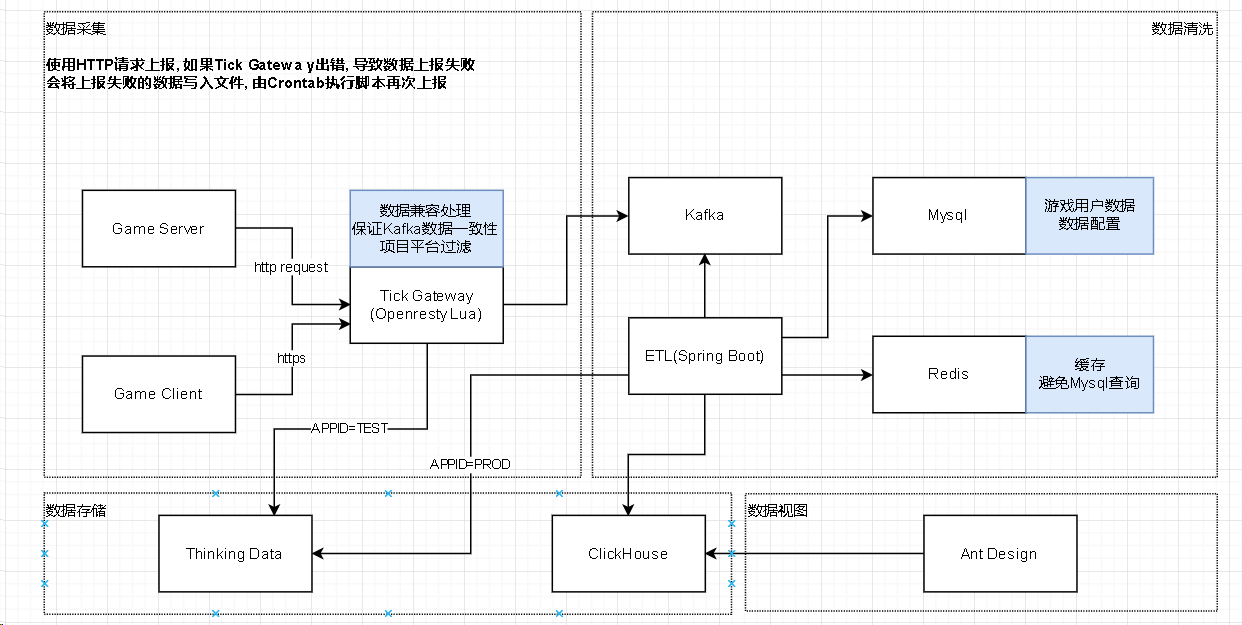
是挺简单的, 从设计上来看不怎么可靠.
因为在测试环境上进行过测试, 但在生产上就问题.
所以只能通过 nginx 的 mirror 模块将生产环境的 HTTP 请求转发给测试环境
来排查问题.
大量 TIMEWAIT 的问题
查看日志, 发现挺正常的, 请求都一个接着一个.
但就是会出现大量的上报失败错误.
看了 CPU, 内存, IO 都挺正常的
因为部分请求是正常的, 所以容器内部肯定会有 TCP 的连接
想抓包看看那些不成功请求发生了什么
进入容器ss -s一看, 有 6W 多个TIMEWAIT
关于 TIMEWAIT 的问题, 网上都讲烂了.
总结一下, 主要为了避免网络上延迟的数据包影响正常的新连接
有两种解决思路.
第一种
开启快速回收, echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
开启重复利用, echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
这两个虽然能快速解决问题, 但是有隐患(往下看)
第二种
避免 TIMEWAIT 的出现.
我们知道, 根据 TCP 的四次挥手的过程
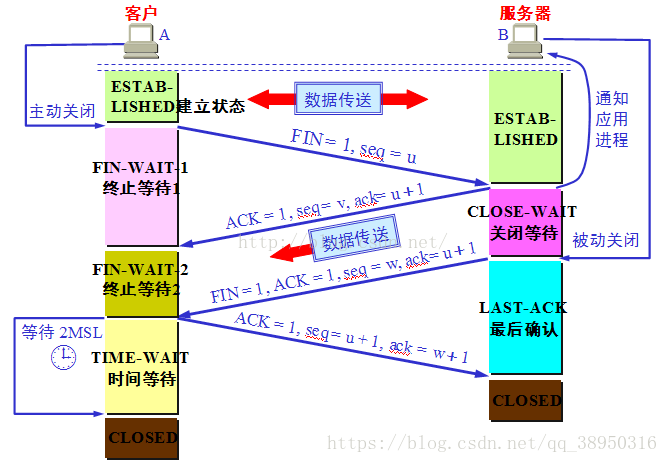
TCP 的服务端和客户端谁先分手, 谁就有TIMEWAIT
所以这种解决思路就是由客户端发出断开的数据包
在 HTTP 的应用层, 有个 HTTP 的头部信息Connection: keep-alive
这个信息控制双方发送完请求后是否断开 TCP 的连接.
HTTP1.0 的默认是``Connection: close, 也就是说, 请求完后立马断开连接. HTTP1.1之后默认的都是Connection: keep-alive`, 请求完等待一段时候.
网上有很多文章介绍, 就不搬运了, 有兴趣的同学自行查找.
现在来看
测试环境上的问题和正常环境无关, 因为正式环境是的请求都是 HTTP1.1
服务端不应该会出现大量的TIMEWAIT
一直没想明白, 后来反复的查找资料和实验才找到答案
测试环境上大量的的TIMEWAIT
是因为 nginx 的proxy_http_version指令默认请求的是 HTTP1.0
这就导致了, 后端服务器处理完请求后就立刻断开连接.
根据我们谁先分手原则, 最终服务器有大量的 TIMEWAIT.
解决方法也很简单
1 | ... |
有点奇怪的是proxy_set_header Connection "";是什么东西.
为什么要清空 HTTP 的Connection信息.
带着好奇心, 问了一下 google.
原来是避免客户端发起了Connection Close, 导致后端服务会和 nginx 直接断开连接.
TCP 数据包时间过期问题
讲了这么多, 还是没有弄清楚生产环境为什么会出问题.
因为无法在测试环境上复现, 所以再次切换到生产环境上了.
还好不是业务系统, 并且有数据有补报机制, 不然可不敢这么玩.
切到生产上, 问题依旧, 赶紧使用 tcpdump 抓包, 然后还原
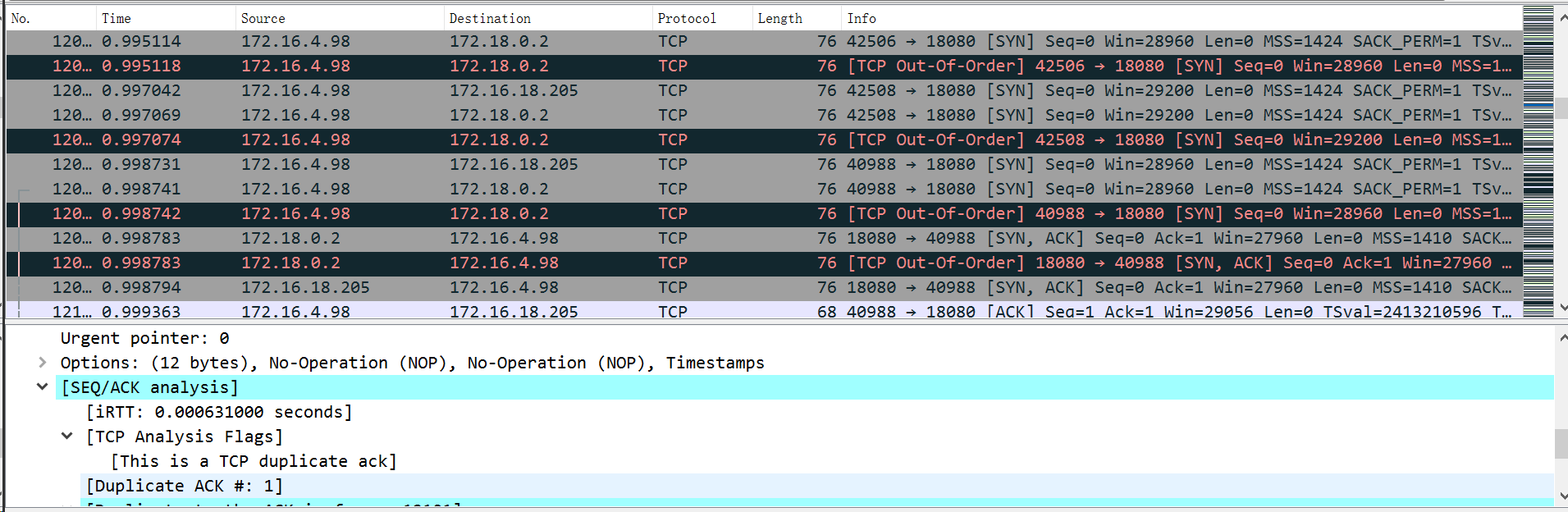
(不是原图, 原图几乎全是TCP Out-Of-Order)
发现全是TCP Out-Of-Order, 简单来说, 就是收到的 TCP 数据包的顺序不对.
因为 TCP 收到数据包后需要校验确认, 来保证双方的可靠传输.
所以收到的 TCP 数据包顺序不对, 无法判断是真的数据丢失, 还是数据错乱.
至于为什么会引起数据包顺序错误, 这个问题其实网上也有很多案例了.
简单来说, 内核文件/proc/sys/net/ipv4/tcp_tw_recycle控制是否快速回收TIMEWAIT的 socket
而 TIMEWAIT 则是用来避免网络上残留的数据影响了正常的通信.
对于同一个连接, 如果收到了过期的数据包就丢弃掉
TCP 使用四元组(源 IP,源 PORT,目的 IP,目的 PORT)来表示一个连接的.
开启tcp_tw_recycle后, TCP 的四元组信息已经不匹配了, 所以只能通过源 IP 来判断
可以通过/proc/sys/net/ipv4/tcp_tw_recycle内核文件来控制是否检查同个源 IP 的数据包时间
除了上面以外, 还有个关键的地方docker swarm使用了ipvs snat将所有的请求都变成一个源 IP
而这些源 IP 收到数据包发现时间不同, 自然会产生丢弃, 最终导致数据无法传输.
复盘总结
- 本来查一个问题, 结果发现的问题越来越多.
- nginx 的 mirror 是一个很好的生产排查工具, 就是要理解好
- 基础性的原理对于排查的思路非常重要.