前戏
其实一开始, 写这东西我其实是拒绝的.
因为感觉没有多少技术含量, 没法体现出我牛逼的地方.
后来想了想, 很多思想和方法还是挺不错, 可以深挖和借鉴.
所以就记录下来, 方便以后回顾.
以上.
问题背景
- 本地数据库使用 5.6 的 MyISAM 引擎.
- 业务没有使用事务, 存储过程, join, 之类的常规关系数据查询
- 直接粗暴简单的将用户数据序列化 json 后存在多个 BLOBTEXT 字段里.
- 每个小时的整点进行锁表备份, 导致 CPU 的间隔性的突发.
我们需要做的是在效率, 安全, 成本之间做平衡
迁移
在游戏服导量过后的一段时间.
需要定期的对游戏服进行迁移.
以提高资源使用率从而降低成本.
数据库在本地时, 迁移需要对数据库进行导入导出操作
既不安全, 效率也低.
备份
本地的数据库使用是的每小时备份.
在备份时会占用本地主机的资源, 影响用户体验.
性能
本地数据库都是机械磁盘
同时大批量的停止和启动服务时会有大量的数据库操作
这些操作大都是磁盘的瓶颈, 拉长了维护的时间
回档
当研发需要查询某个时间的数据时只能按每小时回档
崩溃
没有对数据库做高可用, 当数据库崩溃时影响业务的数据安全
解决思路
在之前项目中, 使用高性能的机器, 搭建 mysql 主从来解决数据存储的问题
现在云设施更完善了, 我们可以通过云数据库来达到目的
云数据库帮我们解决了高可用, 监控, 备份, 安全
这其中任何一项拿来出来都够我们喝一壶的
验证兼容问题
我们之前使用的是 mysql5.6 的 MyISAM 引擎
而云数据库上只支持 Innodb
虽说两者主要是事务的差别, 但不清楚项目使用上是否有什么骚操作
所以我们先将一些没有活跃用户的小平台迁移至云数据库
运行了一周, 看看是否有数据库兼容的问题
这个过程很顺利, 并没有遇到兼容性的问题
迁移过程没有错误, 服务端后台的日志没有错误, 没有用户反馈数据异常.
验证性能问题
一个非常基本的问题.
如果所有游戏服迁移需要多少个云数据库承载.
涉及到业务的写入机制, 活跃用户, 业务性能, 数据安全多方面的因素.
所以我们借助数据库的监控系统来分析业务的性能问题.
经过上线一周来看, 主要有两个问题
- CPU 间隔性突发
- BINLOG 日志过多
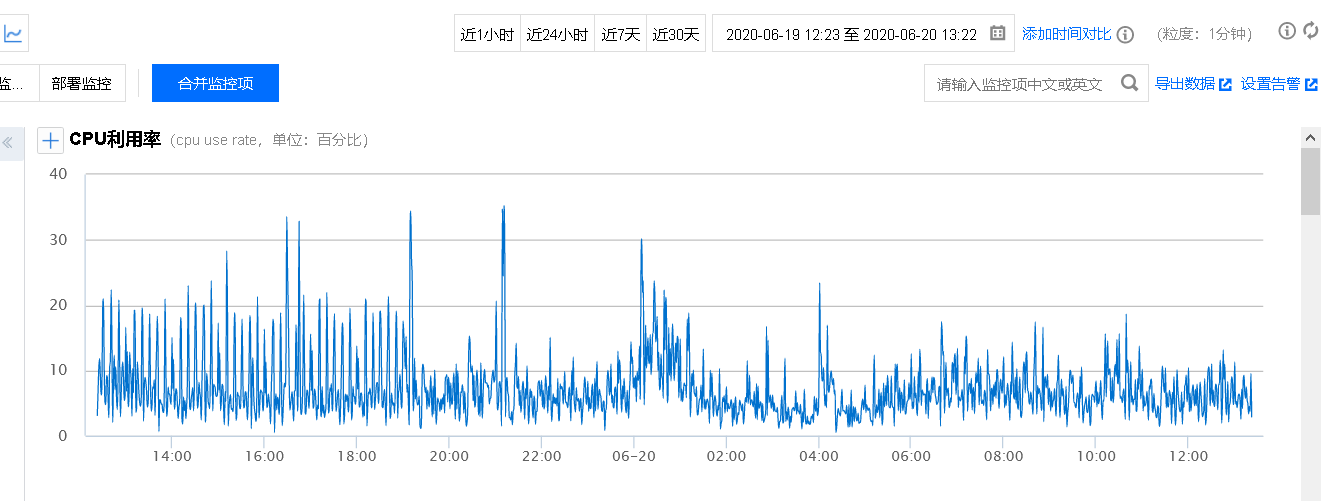
30 分钟的 CPU 间隔性突发排查
CPU 的间隔突发, 主要影响承载游戏服的数量
所以我们需要做的是找到 CPU 突发的原因, 然后削峰
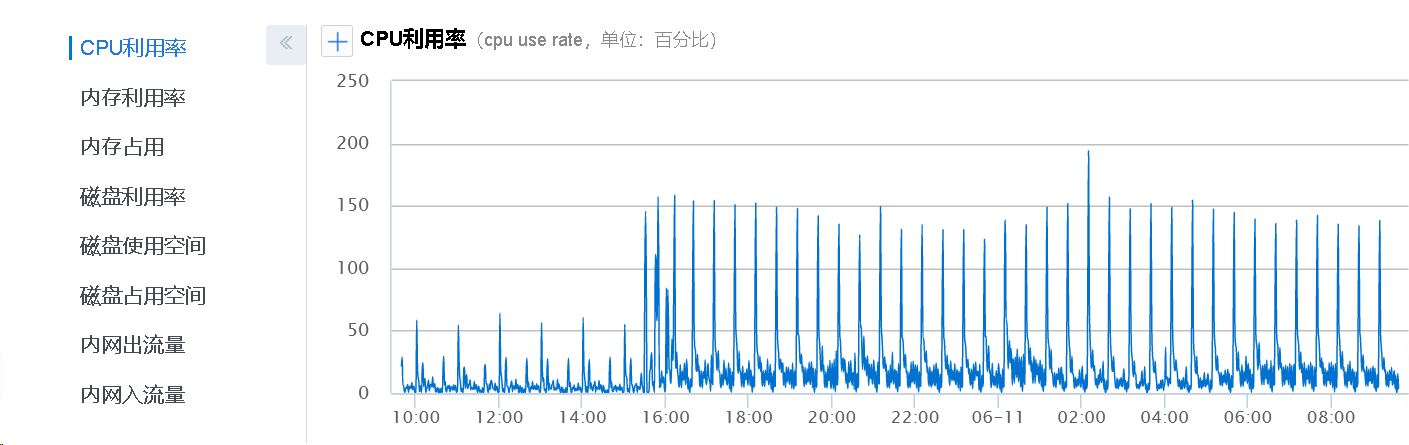
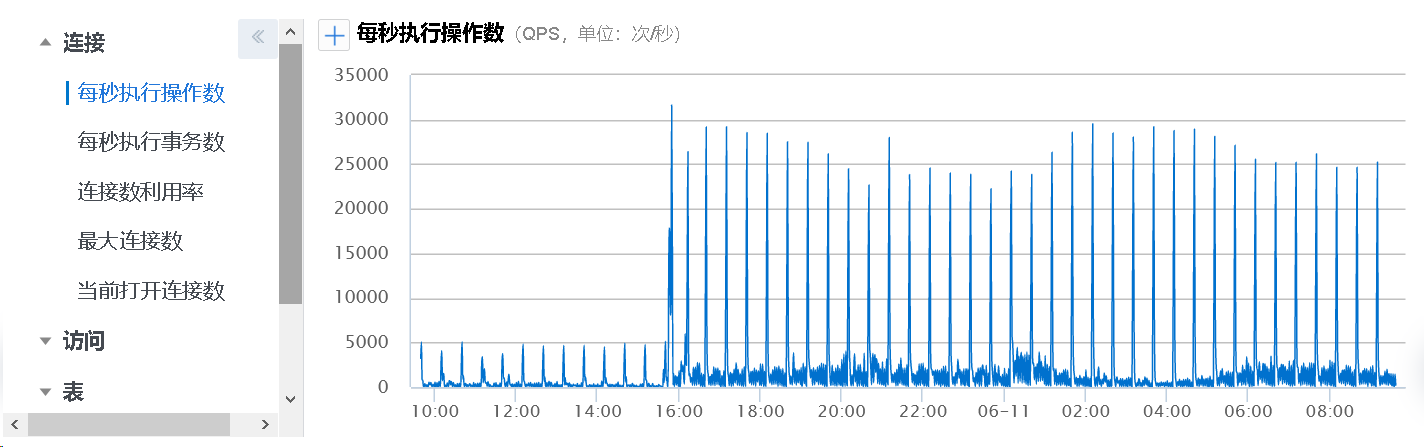
(左边的低突发事因为迁移游戏服的数据库较少)
从监控数据来看, 突发都是每半个小时一次
有个奇怪的地方, 在 03:00-04:00 的时候居然也存在 30 分钟的 CPU 突发
这种明显是不正常的, 毕竟在线的用户少了, 居然还占用这么多资源.
应该是类似的于活动之类的, 但我们的活动都是在 30/60 分钟之类的时间点
我们先找到突发点时间范围的云数据库 sql 的审计(真香), 大量的 sql 语句都是类似于
UPDATE items set field1 = '...' where id = '...'
虽然知道了是哪个表导致的, 但是没法知道是哪个业务系统引起的大量UPDATE语句.
在数据库层面没什么办法了, 只能从业务代码入手.
Sql 注释法
有个思路, 通过 Sql 注释的方式将 Sql 的来源写入数据库.
类似 UPDATE /* SYSTEM_1 */ TABLES set field1 = '...' where id = '...'
和研发沟通后无法实现, 因为 sql 的执行时在数据层, 业务系统在逻辑层
在数据层执行 sql 存储时无法获取逻辑层的信息, 改动的范围太大, 成本过高
打印堆栈法
简单来说, 在数据层入口函数处打印出调用的堆栈信息.
然后根据统计堆栈的信息进行排查.
然而还是有点问题, 每个业务系统调用数据存储的方式都不同
导致打印出的堆栈有不能反映出我们想要的数据.
1 | # 已做混淆 |
从上面的统计来看, 活动模块调用的次数最高.
然后我们再从activityMgr.lua:61来统计, 看看谁调用的次数最多.
经过 2,3 次的统计, 终于找到了源头
1 | # 已做混淆 |
最终和研发沟通后发现逻辑确实有点问题
活动每半个小时会遍历所有的玩家, 而业务需求上只需要查询一次即可
修复之后观察监控数据.
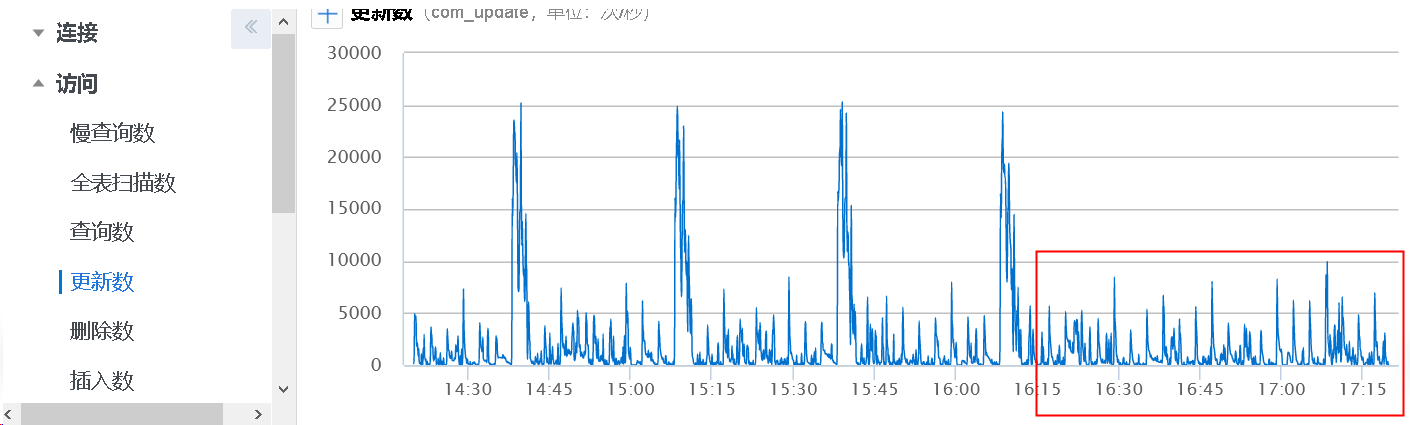
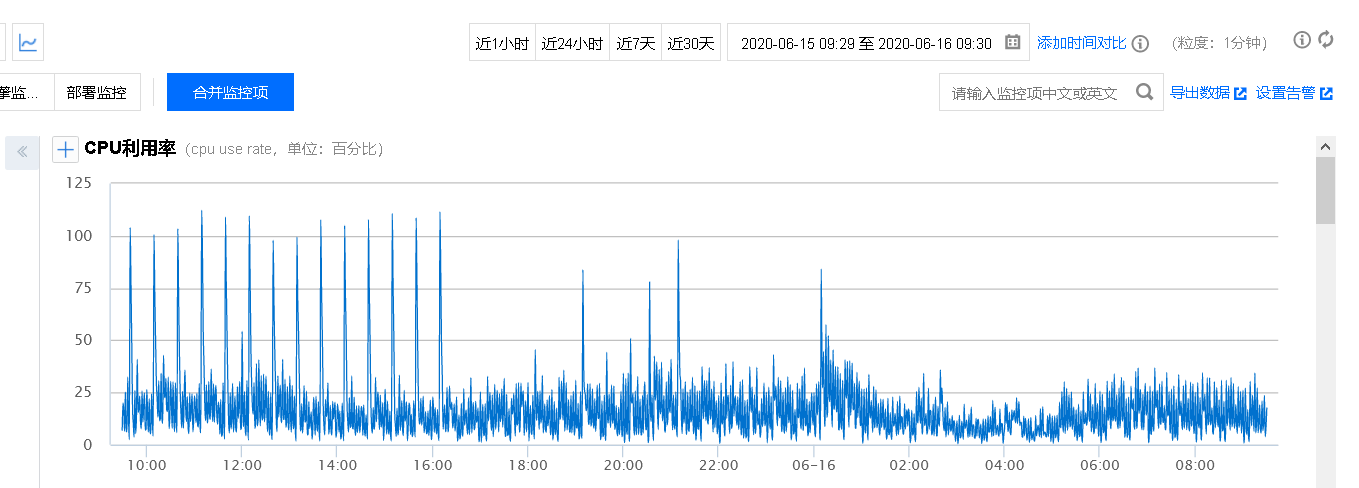
10 分钟的 CPU 间隔突发排查
虽然把 30 分钟 CPU 突发给解决了, 但是在监控上发现, 还是有一些 10 分间隔 CPU 的突发点
这个问题相对好排查一些, 通过云数据库审计系统统计出的 SQL 语句
大部分都是UPDATE mails SET content = '...' where id = '...'
从 Sql 来看明显能够定位到具体的业务系统
通过 Sql 发现大量的邮件内容都是充值 0.01 元导致的
那么问题来了, 为什么充值 0.01 元会导致 CPU 突发?
说来也很是蛋疼的很啊, 系统在设计时, 有这么个逻辑
如果一个玩家登陆, 会将所有的邮件装载到内存里, 避免玩家查邮件因为读数据库卡顿导致操作延迟
如果这个玩家下线, 那么所有在内存里的数据都要强制进行一次数据库写入操作.
恰好, 我们有个用来测试的机器人, 每 10 分钟会在每个游戏服上找个长期(1 个月)没有登陆的玩家
进行登陆测试和充值测试, 这就导致每个游戏服, 每十分钟会有个玩家登陆, 下线, 写数据库.
并且这个操作是立刻的, 所以当有 100 个游戏服的时候就会有 100 个写入操作.
我们默认只保留 15 天的邮件, 按机器人 10 分钟 1 封, 60 * 24 * 15 / 10 = 2160
一个游戏服一次登陆需要读取 2160 封邮件, 然后再写入 2160 封邮件
如果有 100 个游戏服, 那就是2160 * 100 = 216000封邮件, CPU 就是这样被玩坏的.
一开始, 我们想把机器人的测试时间加个随机数, 错开高峰.
但是想想觉得这并不是一个合理的操作, 测试的邮件都是无用的数据.
频繁的读取和写入, 大量的浪费资源, 影响性能.
最后我们决定每次进行 0.01 元充值时, 将机器人登陆邮件全部清空.
这样就避免的测试时大量的无效操作, 观察监控后, CPU 有所下滑了.
BINLOG 日志过多排查
CPU 突发的问题我们差不多都解决了
还有一些突发点是业务需求和修复成本导致的
所以先观察观察, 接着来看看 BINLOG 日志的问题
问题
游戏的架构通常都是在服务内存存储着玩家的数据作为缓存.
所以的数据更新都在缓存进行, 然后定时同步到数据库里.
如果在更新缓存后发生了宕机(系统层和应用层), 就会出现传说中的回档.
缺点就是每次写入数据库的数据比一般的大, 但是没有事务的需求.
当时我们大概估算了一下, BINLOG 的日志一天大概在 260G 左右.
保留七天, 也就是 1800G, 1800G - 500G(免费额度) = 1300G,
腾讯云的 BINLOG 备份日志按 0.008/G/小时算
1 | 1300 * 0.008 * 24 = 249.6 |
一个月光是日志的费用就需要 7488.
还没完, 根据活跃用户, 我估算了下, 大概需要 30 台云数据库.
这样7488 * 30 = 224640, 一个月多了 2W 块的成本, 还只是 BINLOG 日志的.
所以没办法, 必须得进行优化才能上.
思路
我们知道, BINLOG 文件的大小取决于两点Sql次数和Sql大小
所以我们需要根据这两个信息的数据进行判断.
这里先夸一下, 腾讯云的 Sql 审计系统, 做的还不错(也有可以提高的地方)
可以直接将取 1 小时范围内的 Sql 语句来统计次数和大小.
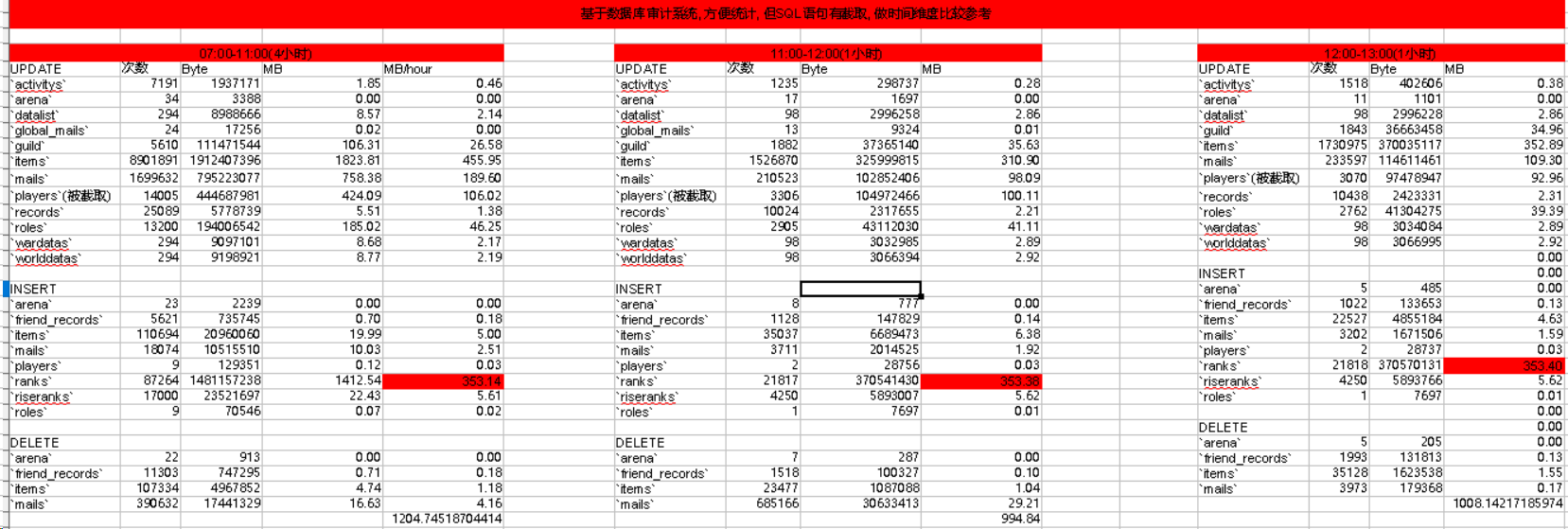
这里有个问题, 腾讯云数据库审计系统上的 Sql 是有部分截取的.
所以没法知道这个 Sql 语句的大小到底是多少, 只能从时间维度上进行对比
而 Sql 语句的准确大小我们要根据 BINLOG 里面的 Sql 来计算
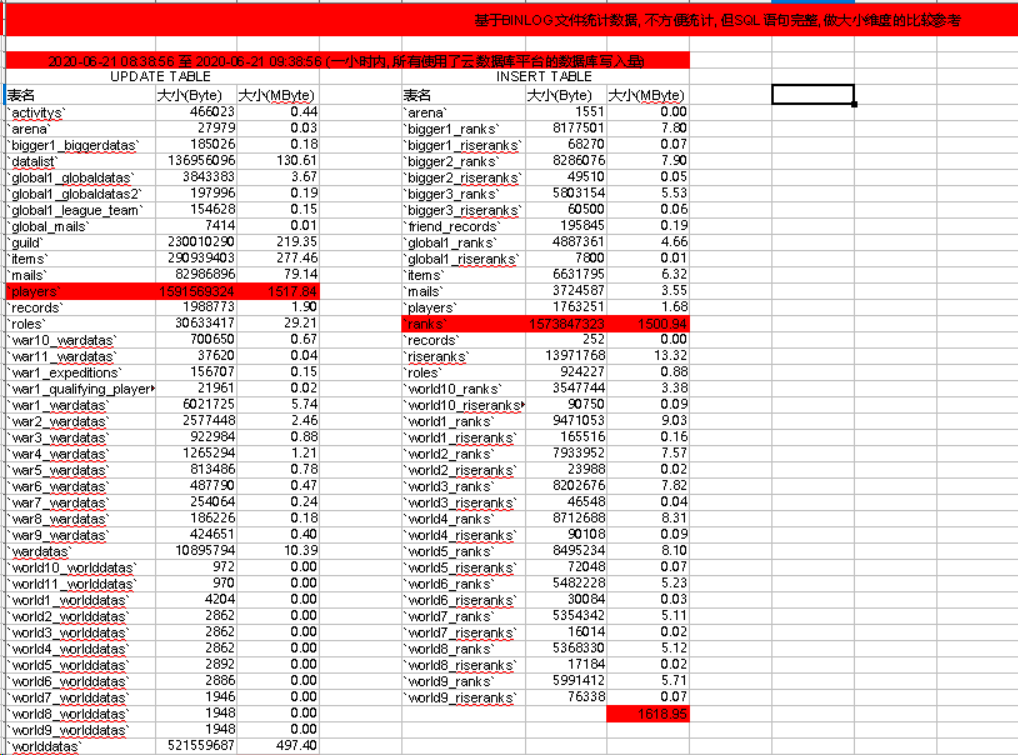
这样我们就能从时间和大小两个维度来比对 BINLOG 大小.
从而发现到底是哪个表和系统有过多的增删改.
可以看到, players表的 Update 的大小最多, ranks表的 Insert 最多.
所以我们需要针对这两个表进行优化.
解决解决
再和研发沟通后得知, players 表示每 3 分钟更新一次.
而 ranks 表示 30 分钟整表清空(不是 delete), 然后 insert.
经过我们的多次尝试, 最后将 players 表改成 30 分钟写一次库
而 ranks 表则 2 小时写一次库, players 表的重要性比 ranks 要大.
所以我们会考虑尽量降低 players 的写入时长, 而提高 ranks 表的写入时长.
完成后观察了下备份的大小, 还行, 在可接受的范围.

复盘总结
- 云数据库监控和审计能够帮助定位了很多问题
- 对业务开发需要制定限制和标准
- 基于数据统计后的执行效果就是快, 准, 狠.