背景
我们是一家 H5 的游戏公司
客户端以网页, 小程序, APP 的方式发布
对 CDN 的请求非常的大, 所以 CDN 请求的影响是非常大的.
前提
其实一开始是想放在 服务端业务异常日志监控 一起讲的
然而因为这里有一些情况不太一样, 细讲起来差异还挺大的.
所以这里就拆开单独写了(真的不是为了凑数!!!)
问题
- 客户端请求 CDN 卡顿
- 客户端请求服务端卡顿
- 客户端代码异常
方案
elasticsearch, 存储检索
logstash, 上报格式转换
kibana, 统计展示
openresty, 上报网关
(和”隔壁”的架构差不多, 只是用 openresty 替代了 filebeat)
看图…
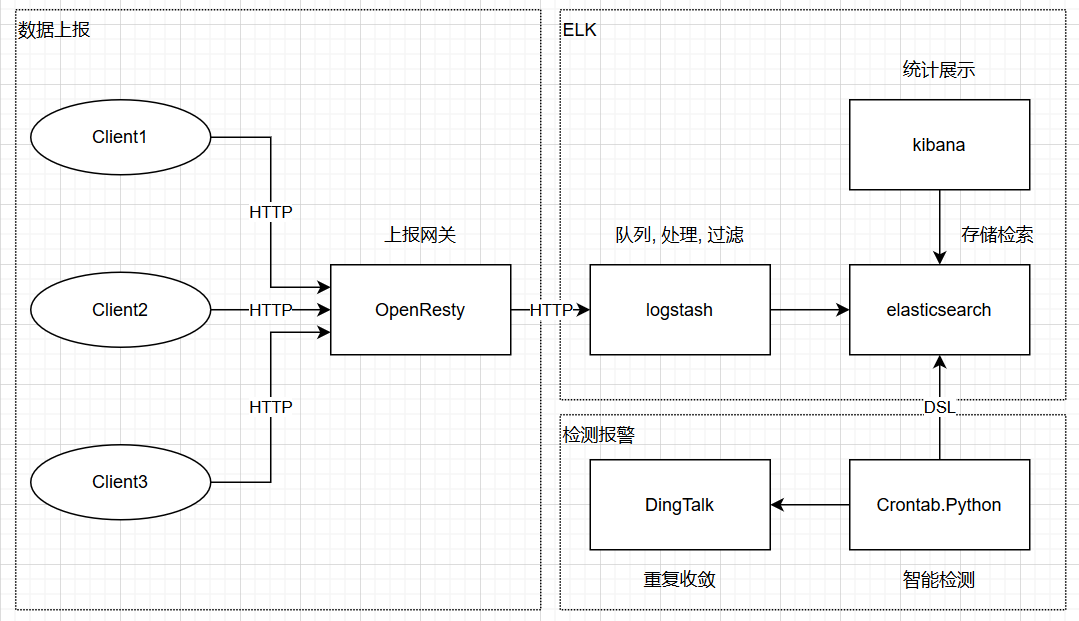
这里之所以没有使用 kafka 还是因为量级的原因, 并且 logstash 自带本地持久化
- 对于数据的并发性没有高要求
- 对于数据的可靠性没有高要求
我们是这么考虑的
- 目前云主机宕机已经很少了
- 而且恰好在宕机的时候把硬盘也搞坏了
- 而且恰好硬盘里还存留着没有发送的数据
- 最后云主机磁盘的 RAID 也跟着坏了.
即使这些情况都发生了, 最多就是丢失一些上报数据, 完全不响应大局
综上所述, 我们没有上 kafka 避免增加维护成本.
实施
ELK
ELK 老生常谈了, 在我们这个数量级的情况下大同小异
没什么特殊的地方, 想看请 出门左转
openresty
openresty 这块, 特意去翻了翻代码
发现也没什么好说的, 就是收到请求后
使用 resty.http 模块向 logstash 发送请求
唯一有点需要注意的是, 我们使用使用 json 格式传输
为了不影响用户的体验, 发生事件后, 将事件数据 push 进一个数组
然后间隔一分钟将整个数组上报
1 | [ |
哦哦哦, 对了, 还有一点需要注意.
因为面向的是多项目的, 所以可能存在不同版本兼容的问题.
可以根据项目对数据格式做解析, 也可以定义版本, 根据版本做解析.
这里是根据项目对解析的, 大概是这么个流程
客户端 -> 网关入口 -> 项目解析 -> 标准格式 -> 请求 logstash
埋点
重点来了, 重点来了, 重点来了
这里最难的点在于需要和不同项目组的人沟通.
- 得先让和他们解释做这个能带来什么
帮助 - 按照文档标准沟通清楚执行并且最后
验收 - 考虑不同项目的情况是否能够
实现
先来看看我们是怎么落地的
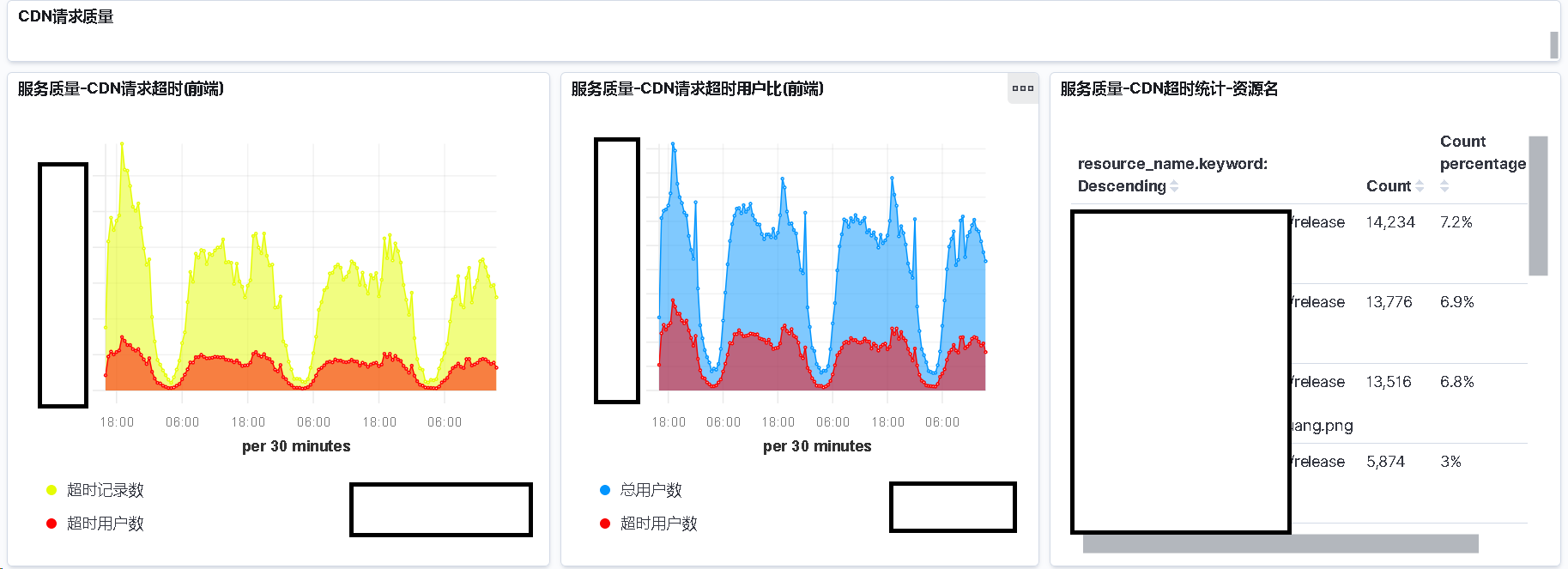
CDN 请求超时
1 | 在http请求开始时记录开始时间. |
CDN 请求失败
1 |
|
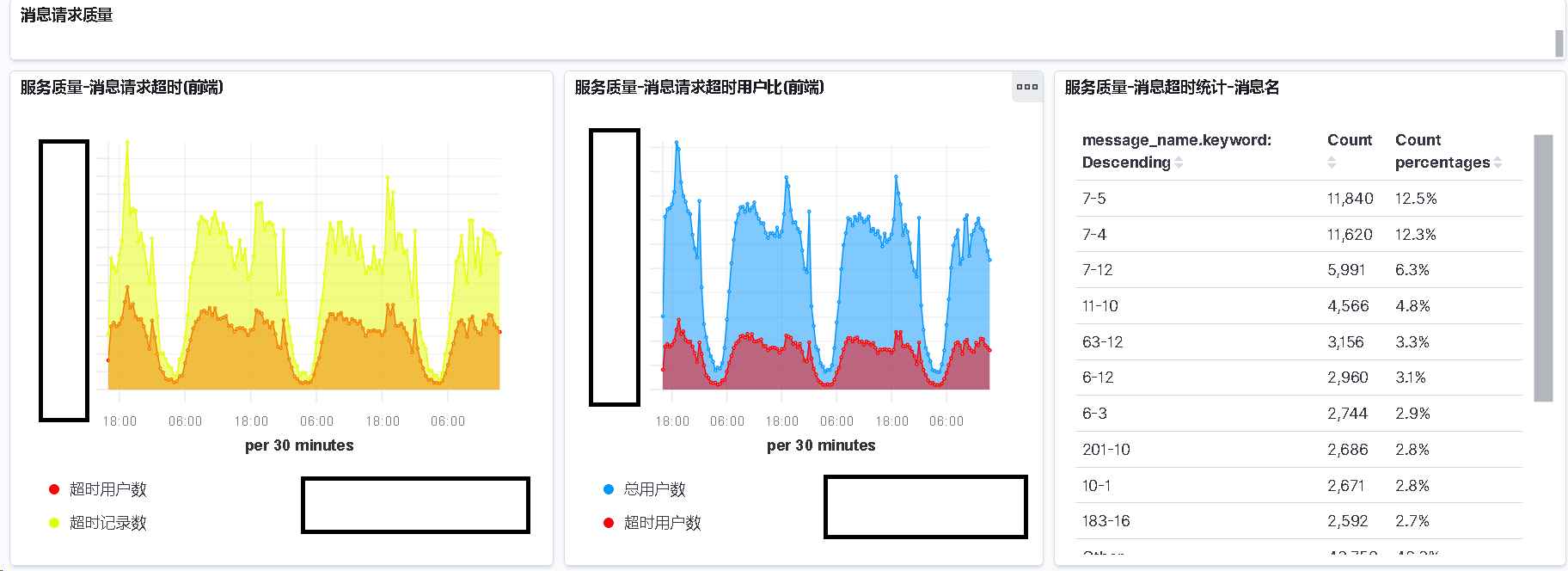
请求服务端异常
这里和 CDN 请求有些类似, 就不重复了.
区别在于, 这个是用于检测用户连接服务器的状态.
可能存在服务端系统问题, 服务端代码问题, 服务端网络问题
同时这个上报也是需要区分项目的
如果项目的消息协议是一来一回的, 比如这样
1 | client ----> client_request_login ----> server |
那这个事情就很好办了, 因为客户端知道收到消息和发送消息如何对应
如果项目的消息协议是一来多回的, 比如这样
1 | client ----> client_request_login ----> server |
那就没戏, 因为没法知道收到的消息对应哪条发送的消息, 也就没法判断了.
有个办法, 在协议上添加一个字段用于请求表示
发送协议时和返回协议时都有对应的请求标识
但是这样改造的成本较高, 而且项目方不一定愿意配合修改
因为投入收益比太低, 所以这一块不太好落地
客户端代码异常
这个其实也很简单, 当客户端代码执行异常时.
触发一个异常事件, 等待下次一起上报.
有个重点是对上报的异常信息要做错误位置截取
这是为了方便统计同一个错误总共发生了多少次
从而优先解决出现率高的异常错误
我们使用 logstash 的 grok 实现的, 虽然效率不高, 但也能满足我们的需求
举个例子
1 | TypeError: Cannot read property 'itemConfig' of null |
像上面的报错信息, 我们需要截取main_6_1100.min.js:2:7760来作为错误位置来进行聚合统计
可以使用下面这个 grok 的表达式来捕获这个错误位置的信息
1 | grok { |
这样就会在上报的数据中添加了一个 fileline 字段来代表异常错误的位置信息.
监控
效果
请求 CDN 监控效果
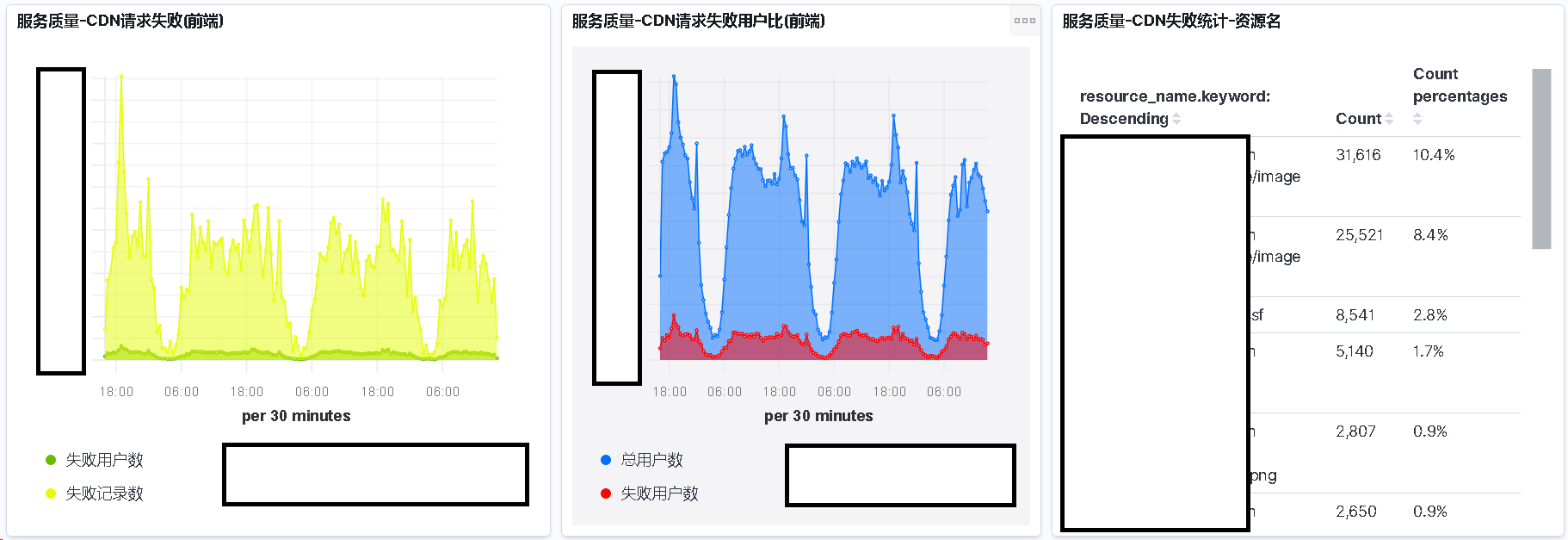
请求服务端监控效果
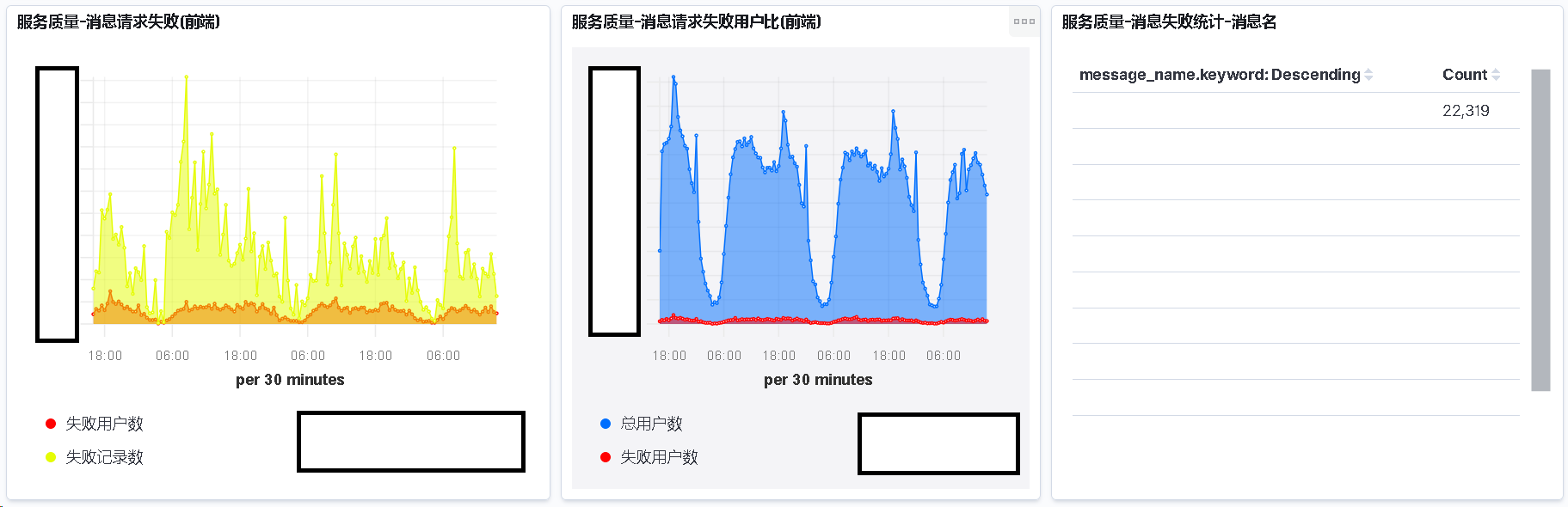
这里解释下, 为什么上图请求服务端的失败统计表为空.
是因为请求服务端失败时记录协议 ID 实现的成本较高
而根据协议 ID 统计出的信息也不具备指导性意见
所以我们就没有纠结这个问题了
客户端代码异常监控效果
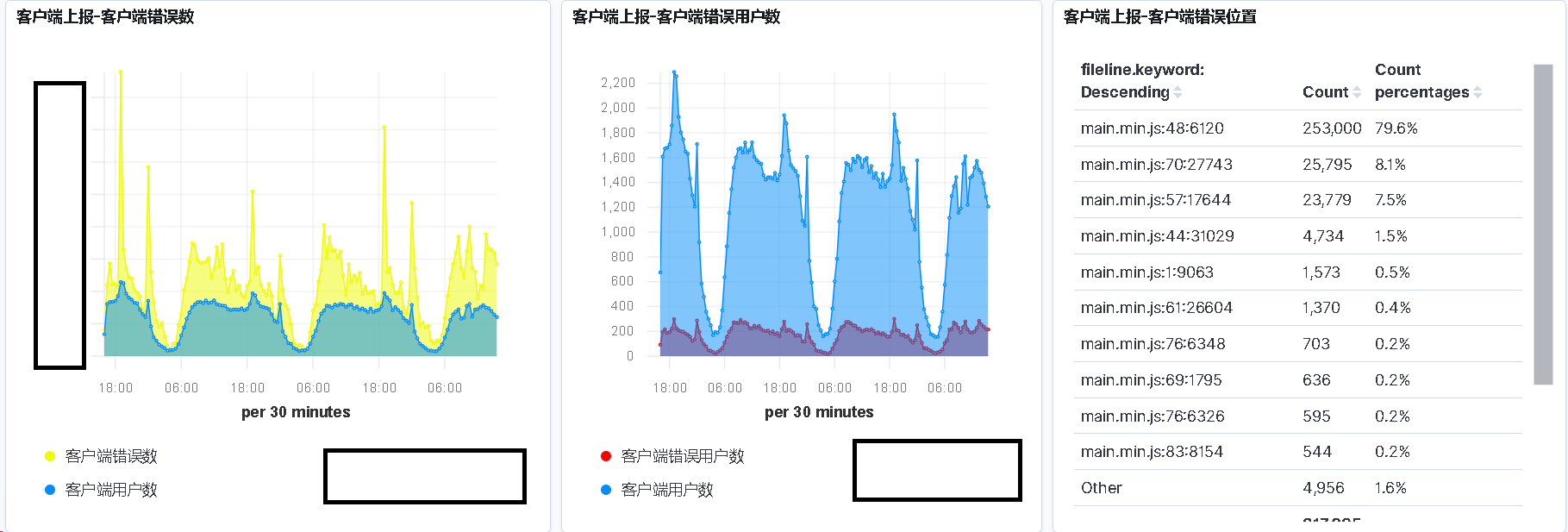
总结
就在写这个 Blog 的同时, 我们业务的 CDN 发生了一次故障.
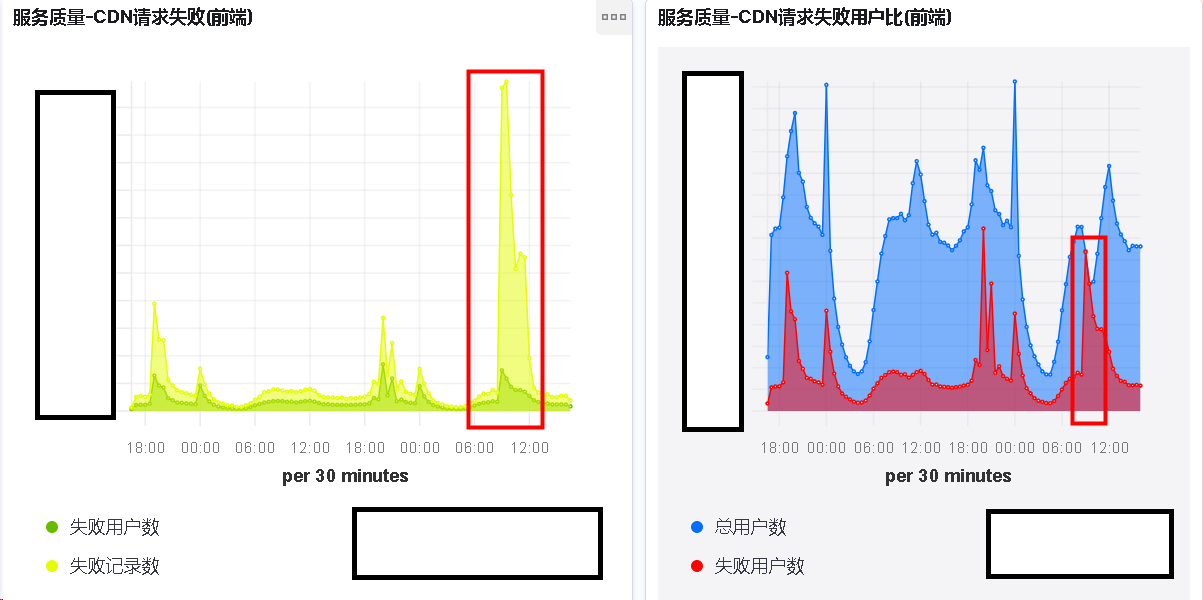
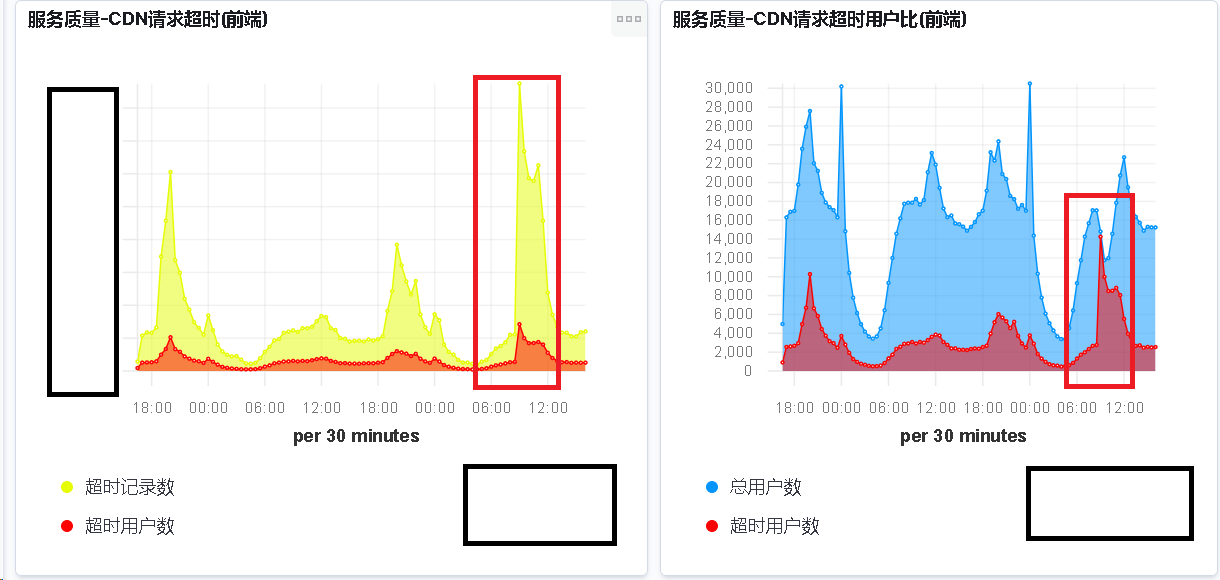
然而我们并没有做相应的监控, 导致响应不及时(主要是没时间精力)
由此可见这块监控效果如何, 如果我们能及时的监控报警
那么整个团队面对问题的响应速度会非常的块, 从而提升我们产品的质量
说了好的, 总要说说坏的.
- 只能被动的发现问题, 但我们的目标是没有蛀牙
- 根据项目的不同, 难以实现统一标准, 维护成本过高
- 监控的覆盖率较低, 只能发现重大问题, 对于平时的运营帮助较小
以上